Your AI Initiatives Are Waiting for Your Data.
Most companies start an AI project and hit the same wall: data scattered across systems, no unified access, no clean pipelines. Building the foundation takes months. Meshly Data Stack gets you there in days. On your infrastructure. Your data never leaves your environment.
Open source. Self-hosted. GDPR-compliant by architecture.
The AI Bottleneck Nobody Talks About
Your CRM has customer data. Your database has transactions. Your team uses spreadsheets. Some data lives in cloud storage nobody fully controls.
When you start an AI project, you quickly find out: the AI is not the hard part. Getting clean, unified, accessible data is.
The conventional answer is hire a data engineer, spend 3-6 months building a stack, integrate everything manually, figure out security and governance along the way. By the time it's ready, your AI initiative has lost momentum.
There is a faster path.
AI-Ready Data Infrastructure. Running in Days.
One command deploys a complete data platform. Pre-integrated, pre-secured, managed by AI. Your team focuses on AI work, not infrastructure.
Unified Data Access
Connect your databases, streams, files, and APIs into one platform. Query everything from one place. No moving data between systems, no vendor-specific query languages. Your AI tools get clean, structured access to all your data from day one.
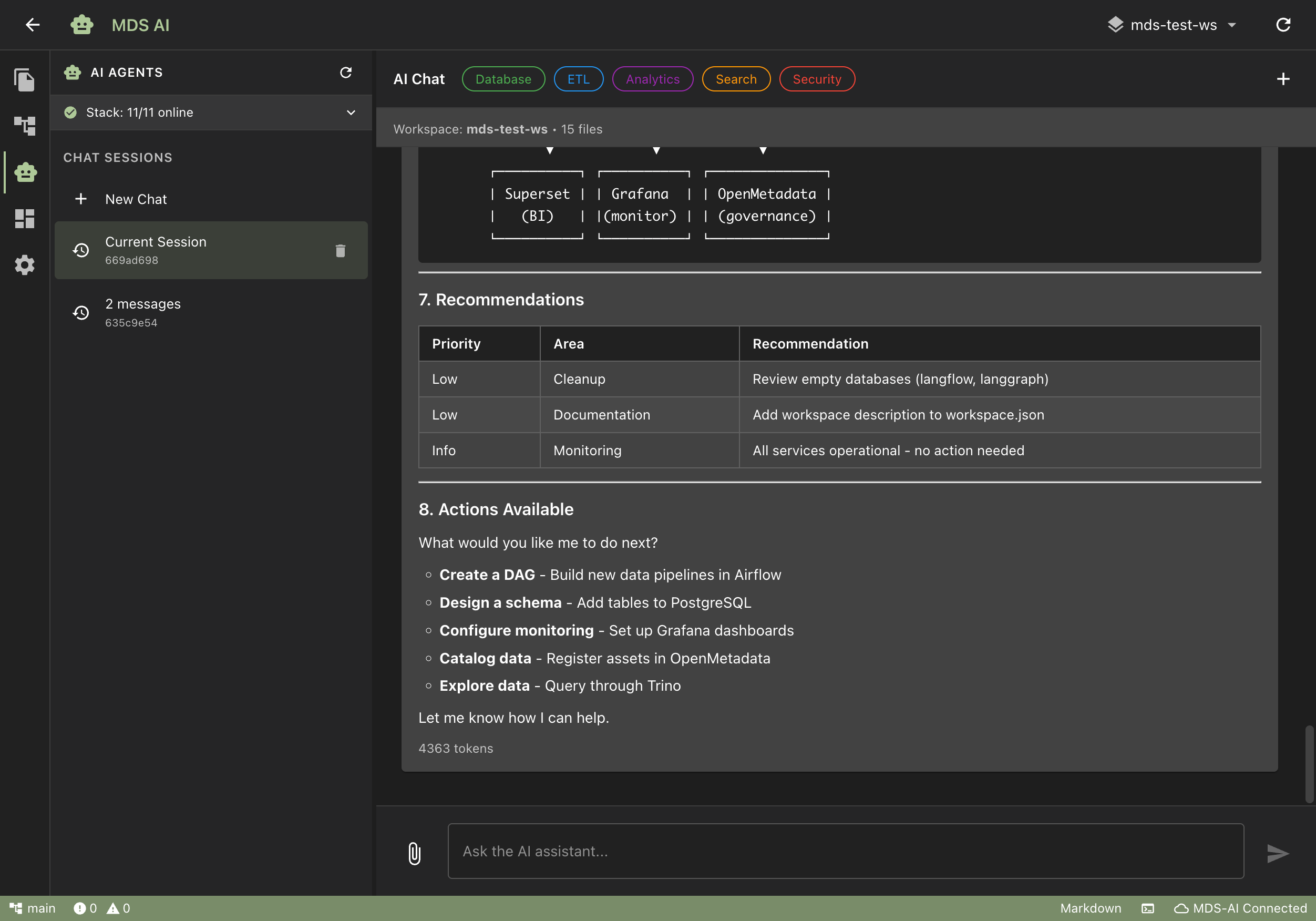
AI That Runs the Platform
Eight specialized AI agents manage your databases, build your pipelines, create dashboards, serve APIs, and monitor the entire stack. Problems get fixed before your users notice. No dedicated data engineer required to keep it running.
Your Data, Your Infrastructure
Deploy on your own servers, your EU cloud, or hybrid. Full GDPR compliance by architecture, not policy. No vendor access to your data. No phone-home telemetry. Complete isolation. When US cloud contracts become a board-level concern, this matters.
From Scattered Data to AI-Ready in Days
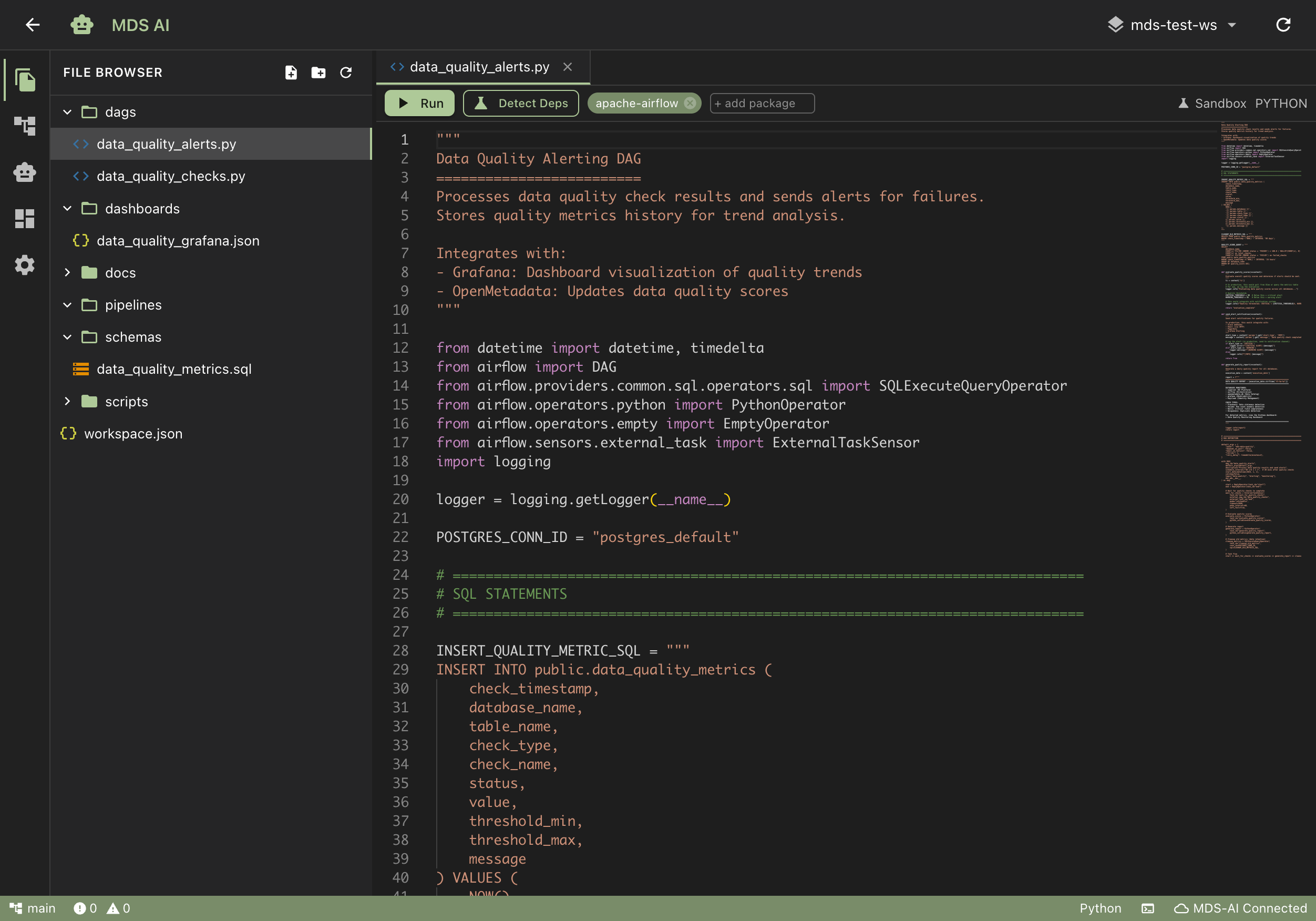
1. Deploy
One command starts 25+ pre-integrated services. Security configured, services connected, monitoring running. No integration project. No configuration drift. Ready for production from the start.
2. Connect Your Data
Point MDS at your existing systems. Databases, APIs, files, streams. The platform ingests, normalizes, and makes your data queryable from a single interface. First integrations running within a day.
3. Put AI to Work
Your AI tools connect directly to your unified data layer. MDS AI manages the platform, builds dashboards on request, creates APIs from plain language descriptions, and keeps everything documented and running. Your team focuses on what the data tells you, not on keeping the infrastructure alive.
What This Looks Like in Practice
A European company with €30-100M in revenue. Three to five people in the tech team. Leadership has committed to AI. Maybe a pilot is already running. Maybe the board is asking questions.
The data team starts pulling the thread. Customer data in the CRM. Transaction data in a separate database. Operational reports in spreadsheets. Some historical data in cloud storage. No unified access. No clean pipelines.
The AI project stalls. Not because the AI is wrong. Because the foundation is missing.
The conventional path: hire a specialist, spend months building, maintain it forever.
With Meshly Data Stack: deploy in minutes, connect your data sources in days, hand platform management to AI agents. Your team starts working on the actual AI problems within the first week.
“A comparable managed cloud stack costs €50,000-200,000 per year. Meshly Data Stack runs on your own infrastructure at a fraction of that cost.”
Everything the Foundation Needs
Built on proven open source technology. Pre-integrated, pre-secured, AI-managed from day one.
Unified Data Access
Query all your data sources with one SQL interface. No data migration, no vendor lock-in, no learning new query languages.
Real-Time Data, Always Current
Database changes flow into your analytics layer automatically. No nightly batch jobs, no stale dashboards, no manual ETL.
Dashboards Without a BI Developer
Describe what you need in plain language. The AI builds production dashboards with approval workflow. No BI specialist required.
APIs Without a Backend Team
Create REST endpoints from a description. Caching, rate limiting, and API key management included. Zero deployment pipeline needed.
Security That Manages Itself
Every credential generated and rotated automatically. Single sign-on across every interface. Row-level access policies per query. Zero hardcoded credentials.
Your Data. Your Infrastructure. Your Rules.
Full data ownership. Deploy on-premises, in your EU cloud, or hybrid. GDPR-compliant by architecture. No vendor data access. No phone-home telemetry.
Platform Watches Itself
Autonomous monitoring detects issues, restarts services in the right order, and alerts your team. Problems fixed before users notice.
Governance From Day One
Data catalog, lineage tracking, and quality monitoring built in from the start, not bolted on later.
From Laptop to Enterprise. No Migration.
Evaluate on a laptop. Deploy to production. Scale to enterprise. Same platform, same security, same configs at every stage.
Documentation That Maintains Itself
AI generates and updates technical documentation as your stack evolves. No outdated wikis, no lost institutional knowledge.
Built on 25+ integrated open source technologies
No Black Boxes. No Vendor Lock-in.
Every component is a proven open source technology you already know. 25+ services, pre-integrated, pre-secured, and ready to run.
Messaging & Streaming
Query & Analytics
Storage
Orchestration
Visualization
Security
Monitoring
MDS AI Layer
AI Framework
Modular by Design
Clean separation between layers. Every component replaceable, every layer extensible. No lock-in at any level.
Visualization
Data Serving
Query & Analytics
Orchestration
Processing
Storage
Monitoring
Security
Unified pod network with single sign-on across every service and AI-managed orchestration
Runs Where You Need It
Same platform at every stage. No migration project between environments.
Laptop
Development
Evaluate the full platform on your own machine. Same security, same configs as production.
Requirements
16GB RAM, 8 CPUs
macOS or Linux
Podman Desktop
Full feature set
Server
Cloud
Deploy to your own servers or EU cloud. Automatic SSL, reverse proxy, subdomain routing. Production-ready in one command.
Requirements
32GB+ RAM, 12+ CPUs
Linux (RHEL, Ubuntu, Debian)
Podman, Nginx, automated certs
OpenShift
Enterprise
Architecture-ready for Red Hat OpenShift. Same platform, same security, scales to enterprise. No migration project, no configuration drift.
Requirements
OpenShift 4.x / Kubernetes
Rootless Podman-native containers
Red Hat ecosystem compatible
See It in Action
Explore our dashboards and demo applications
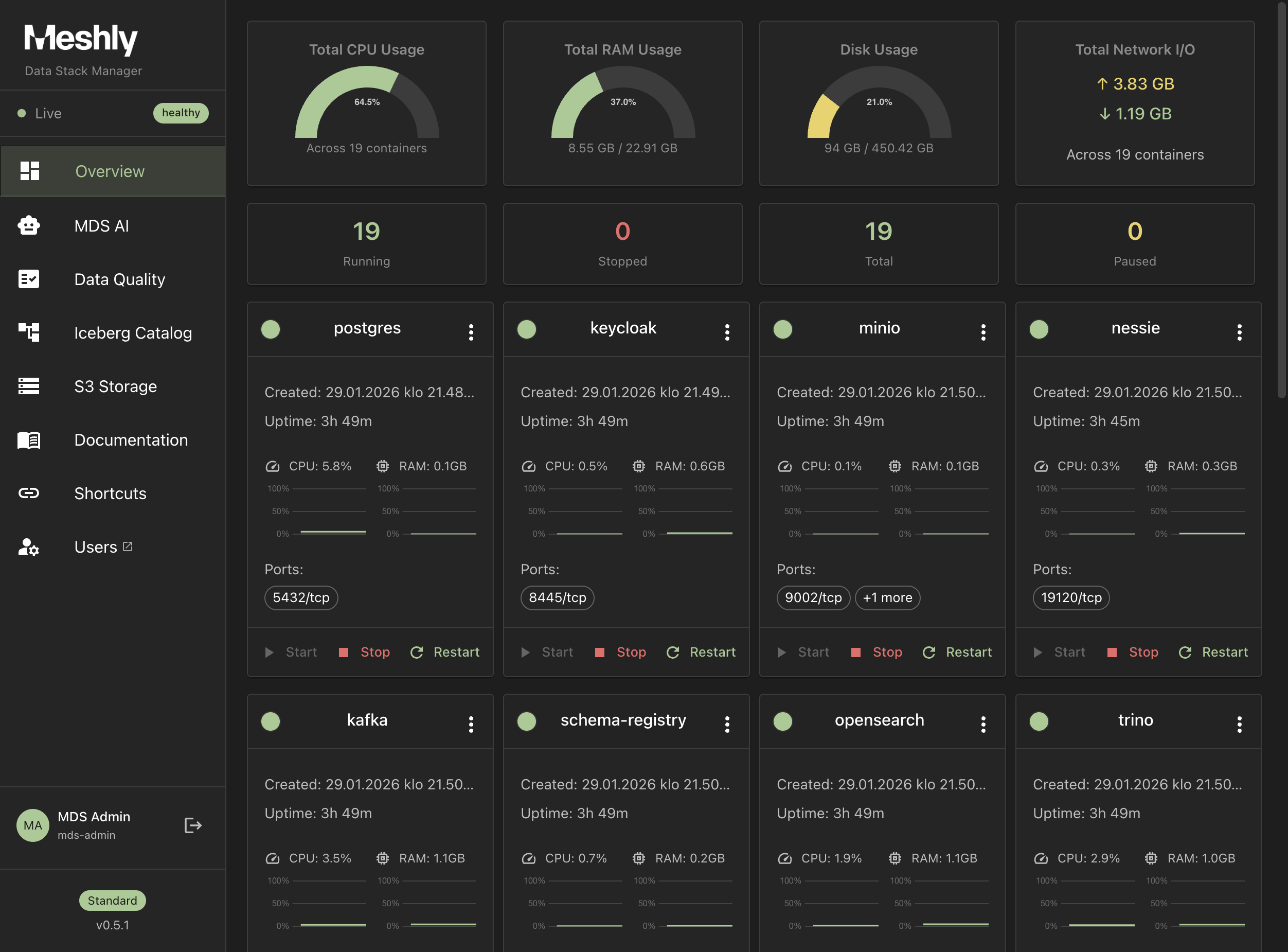
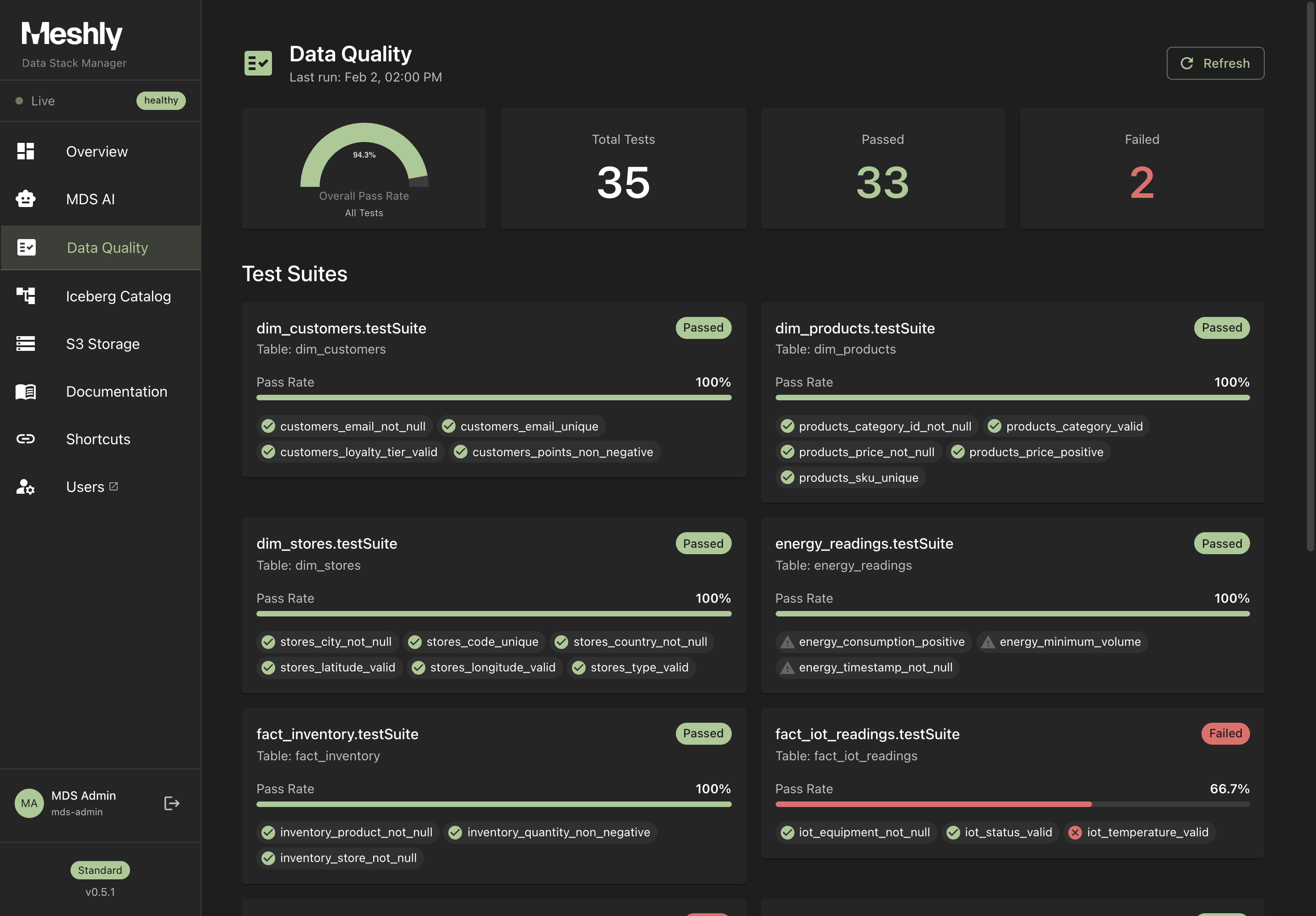

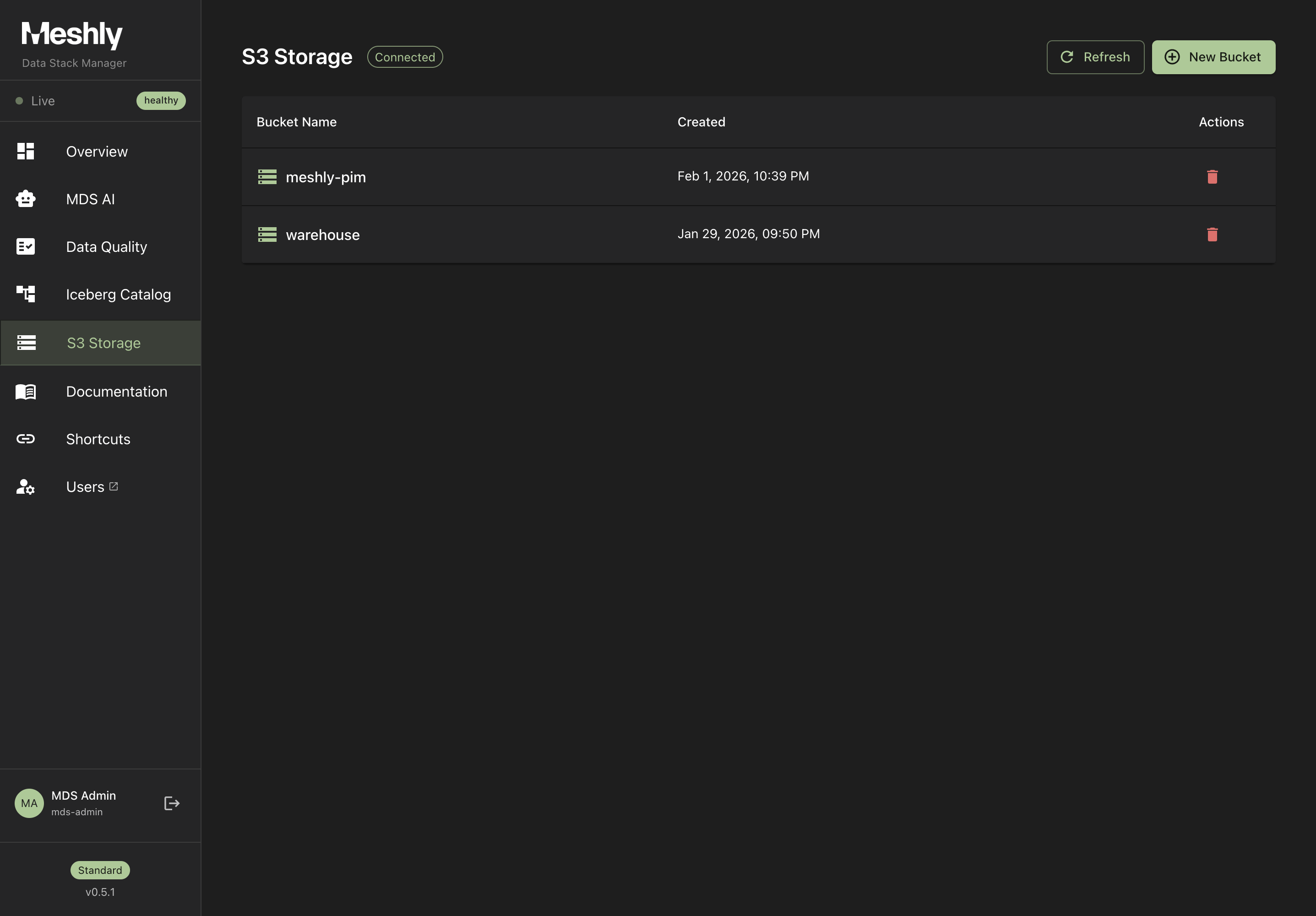
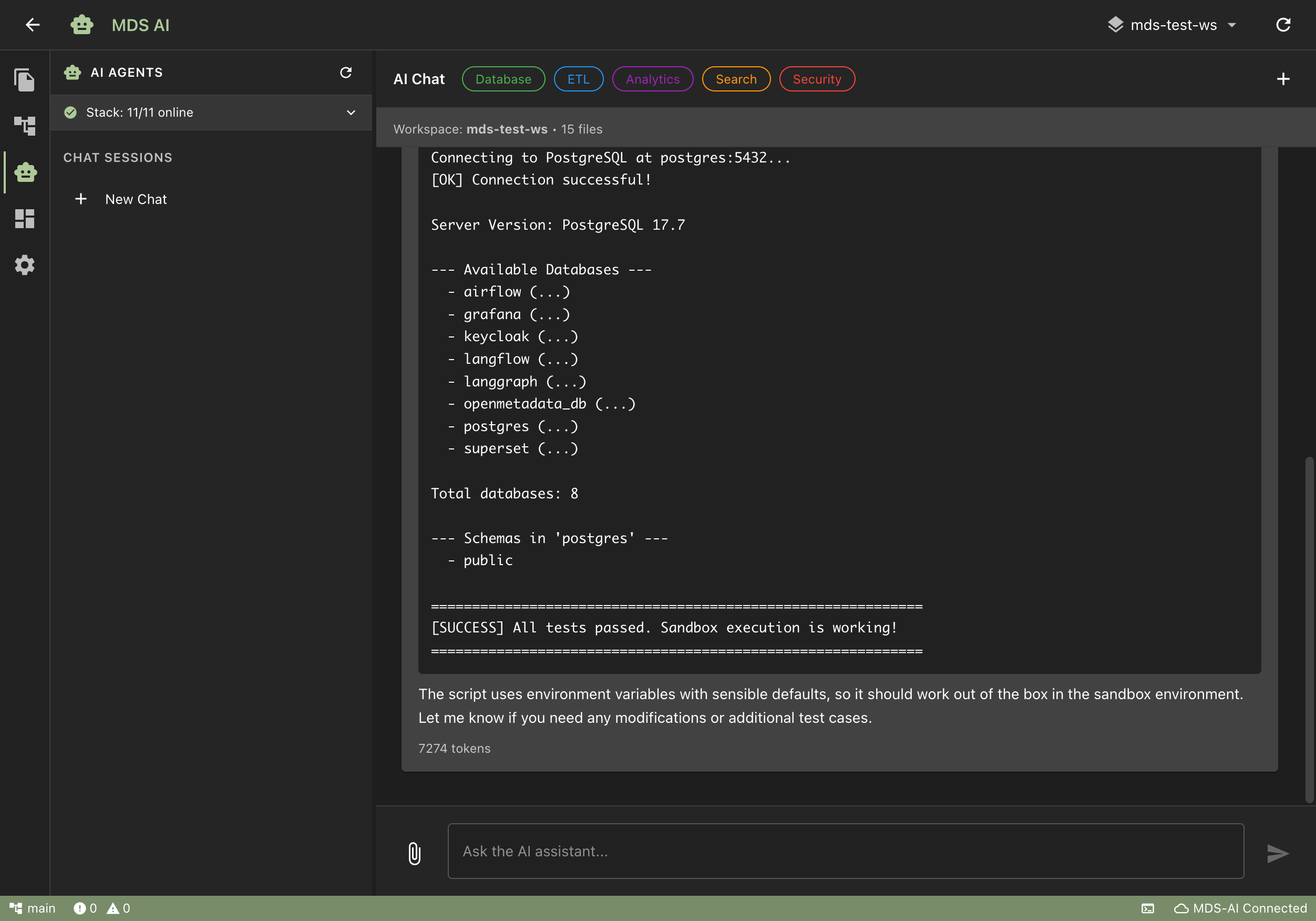
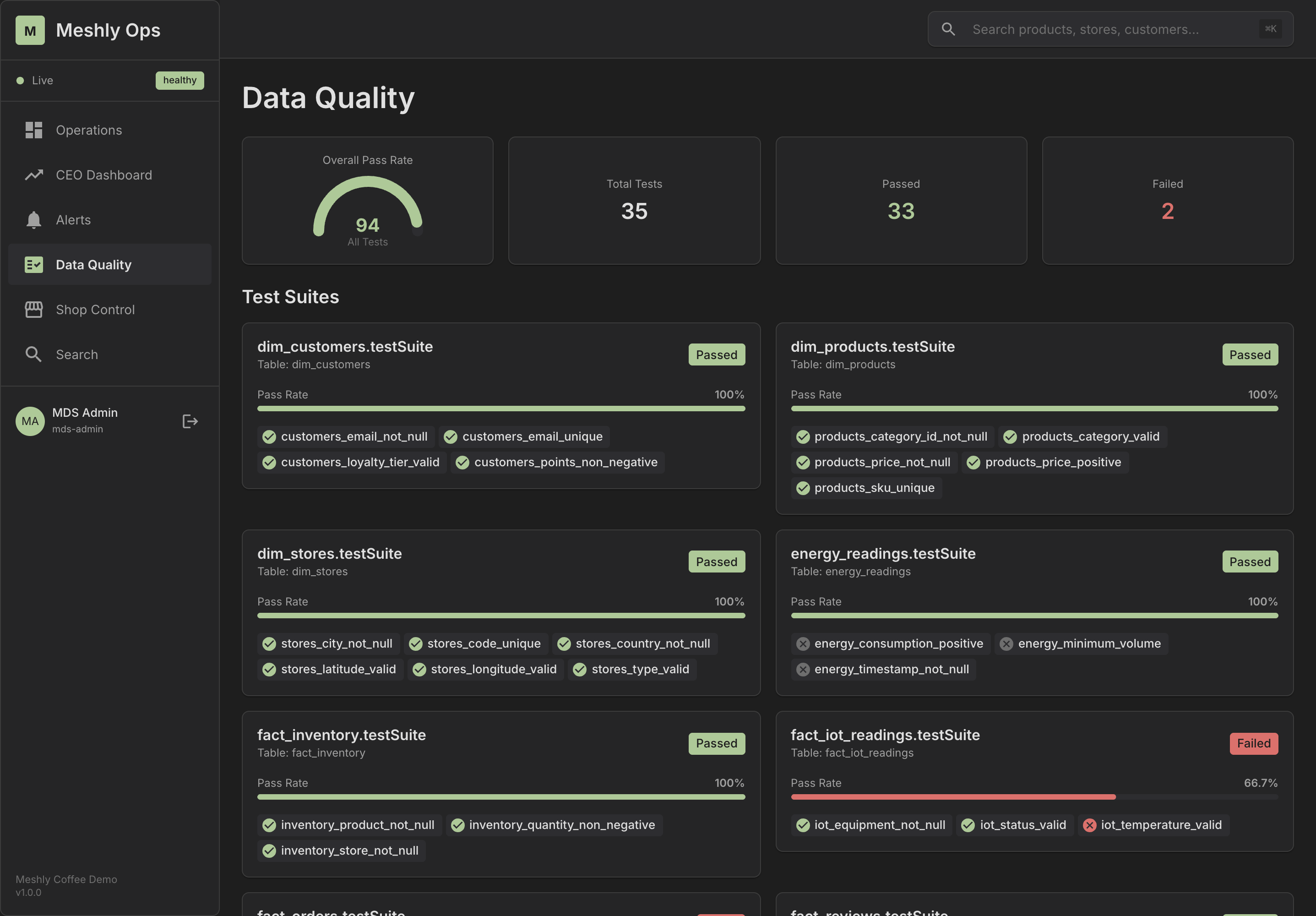
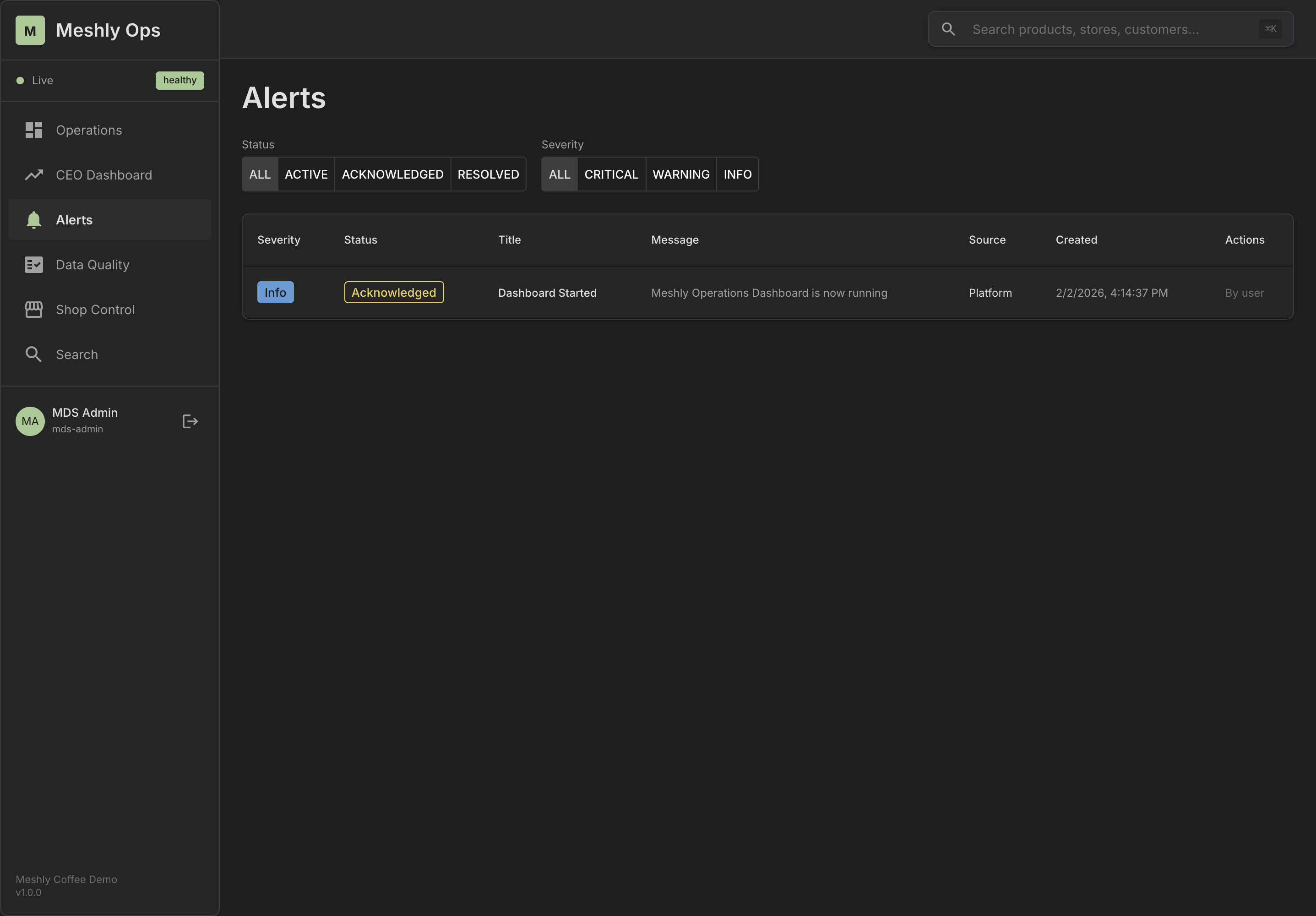
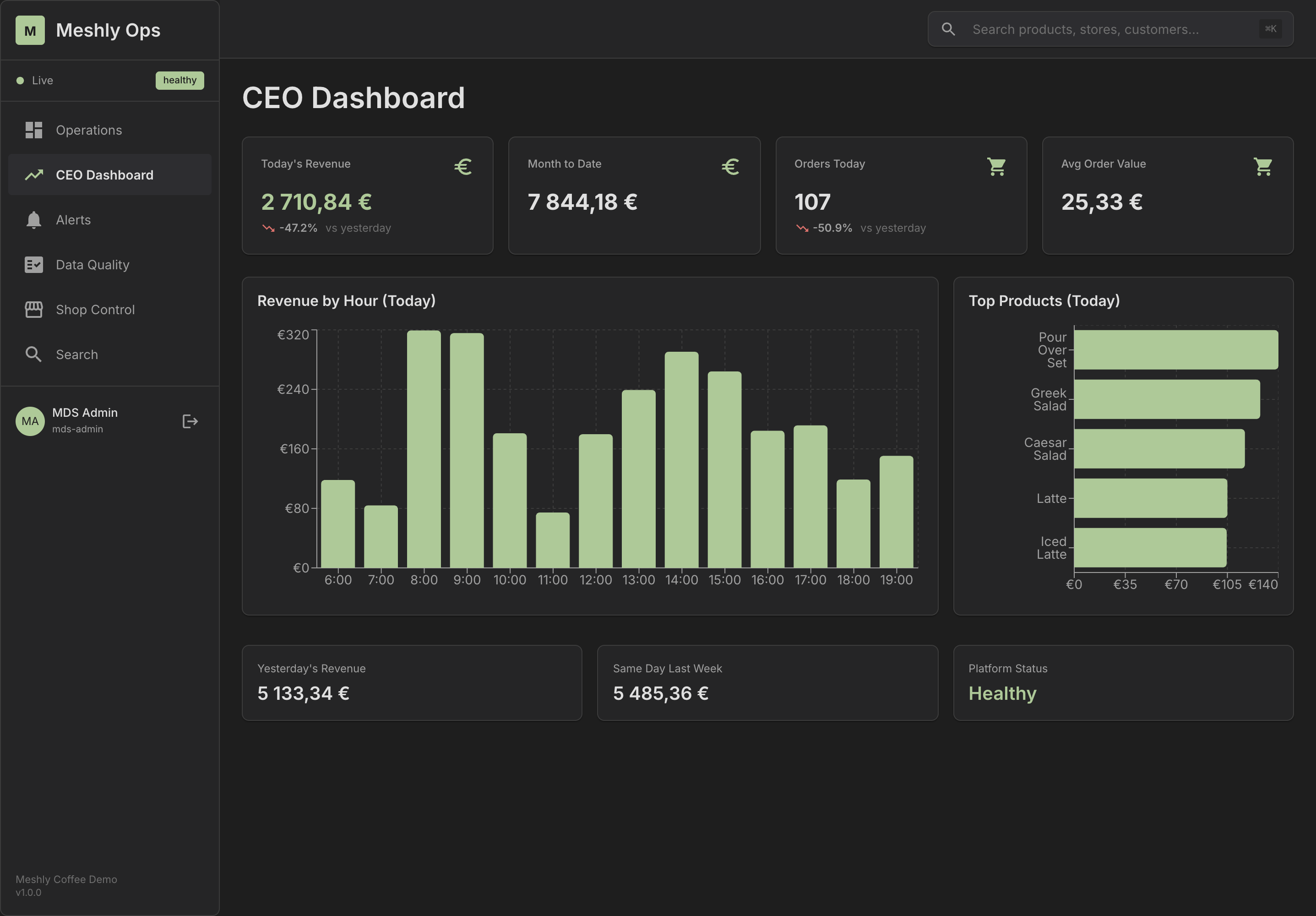
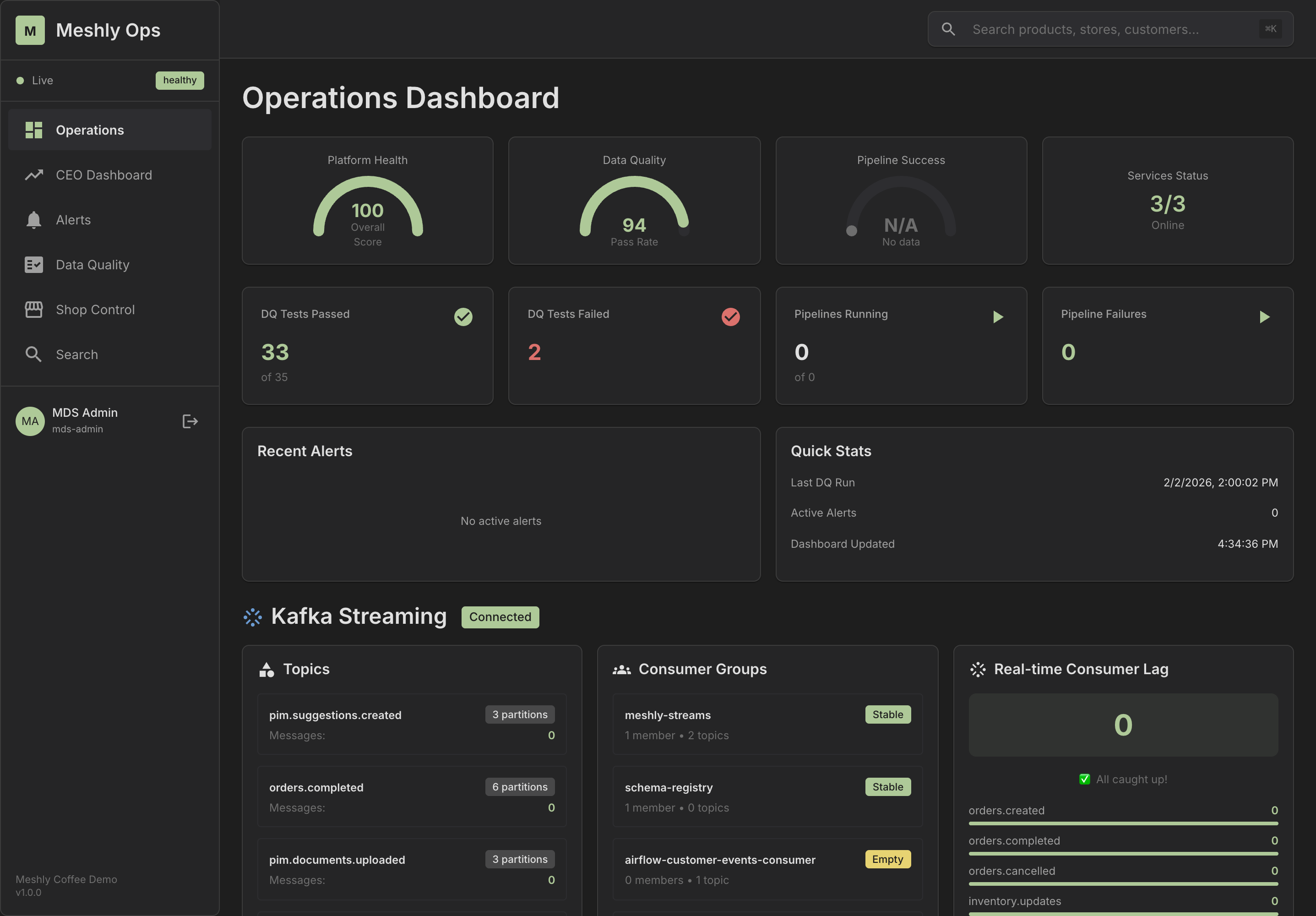
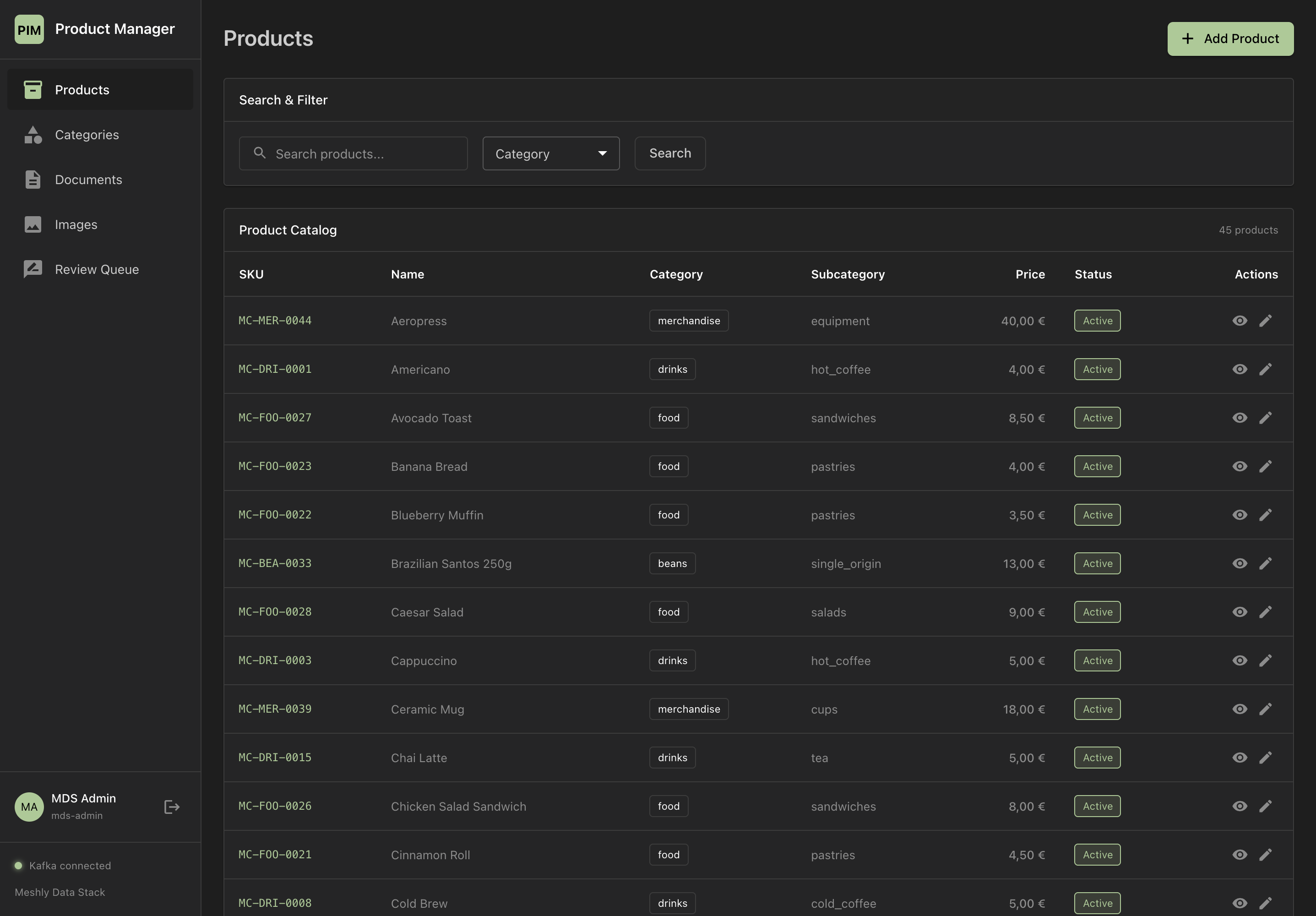
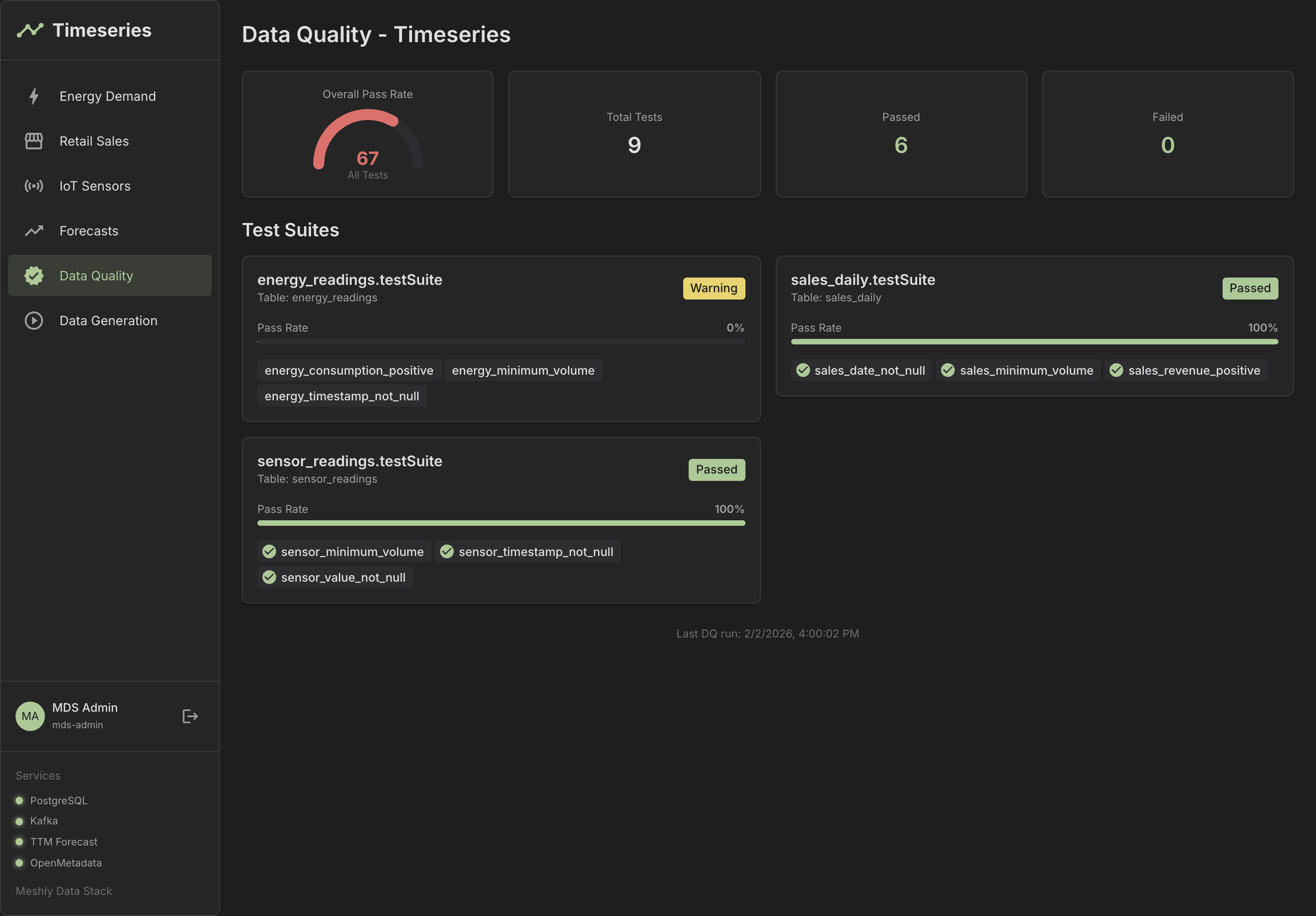
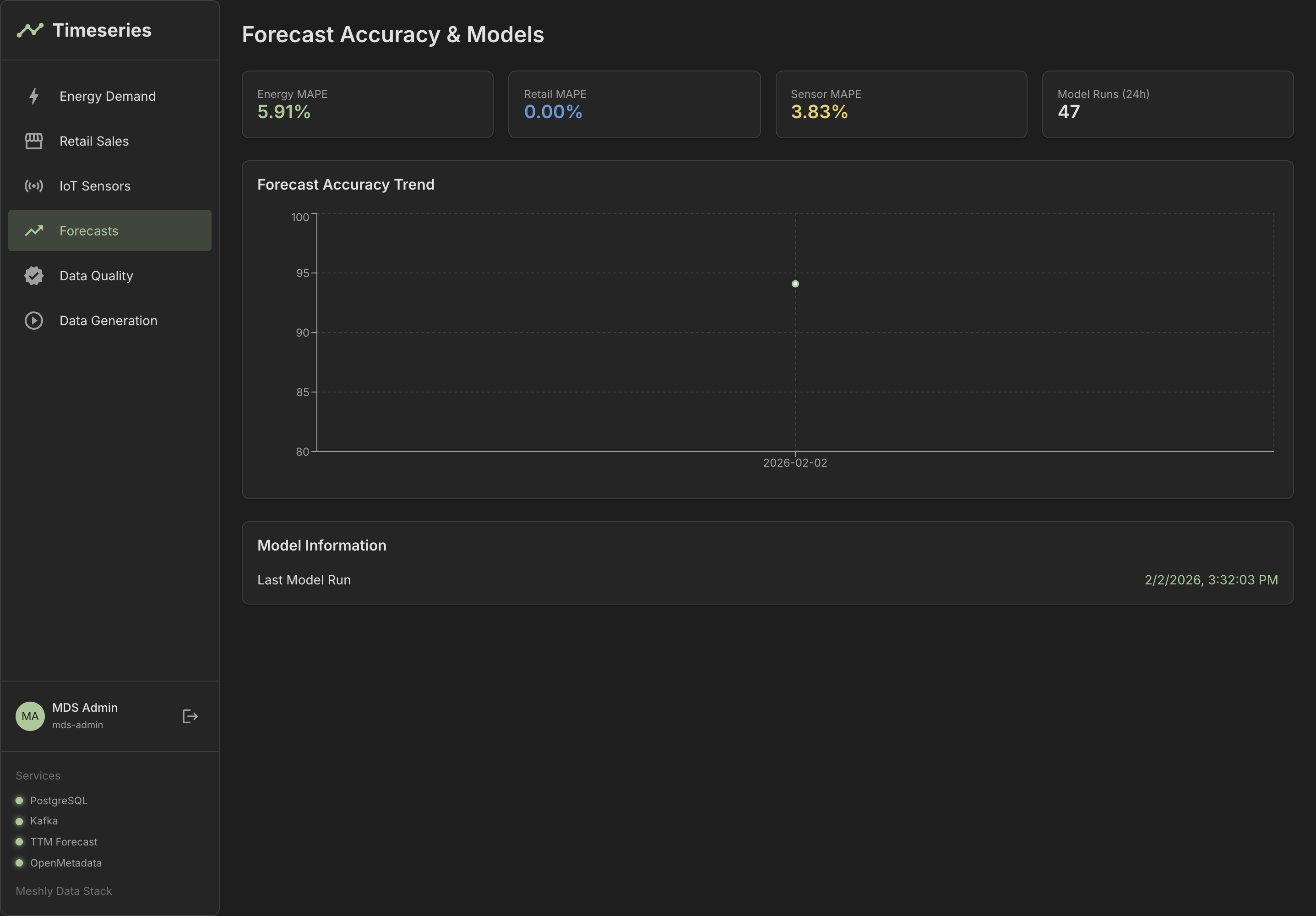
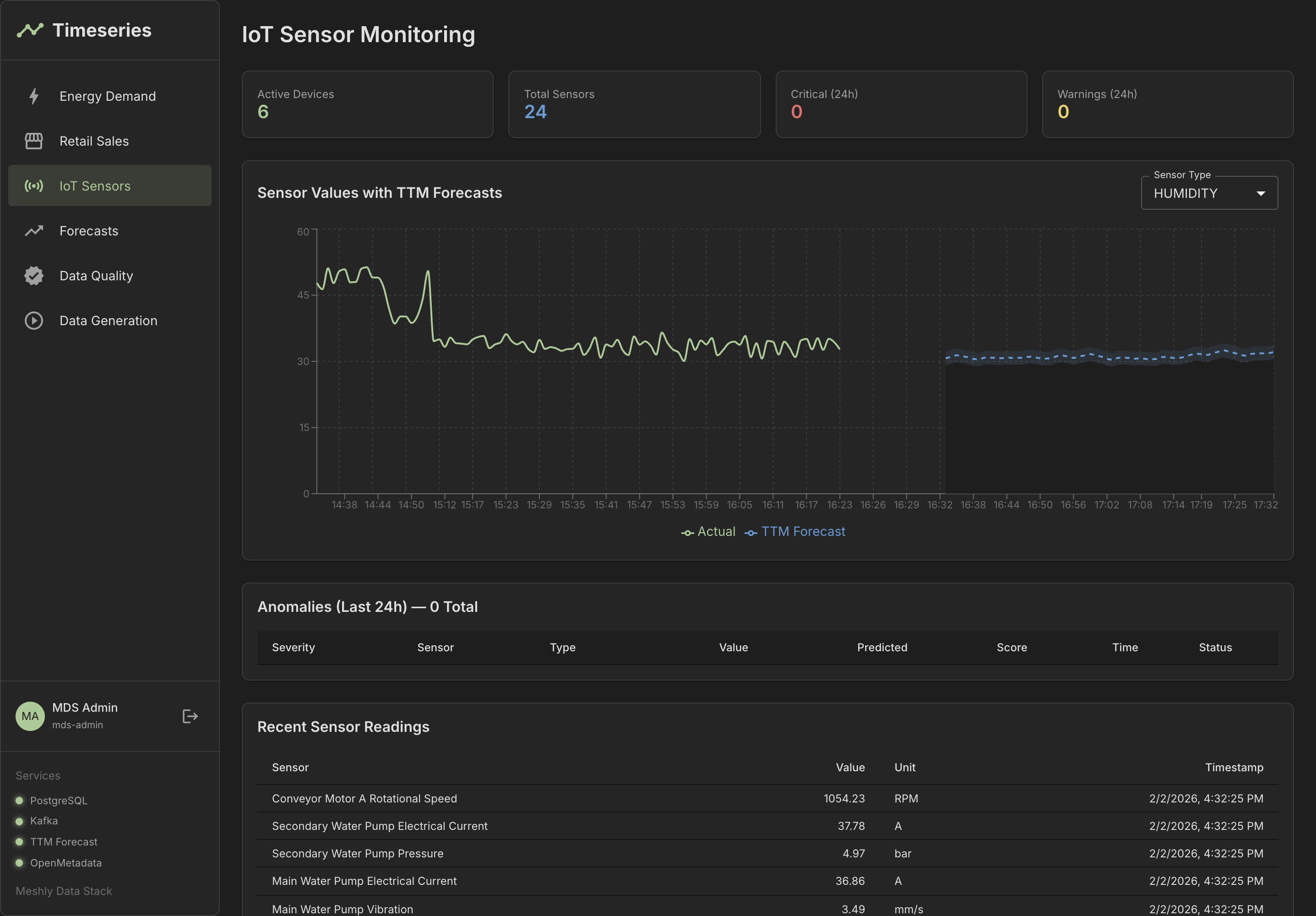
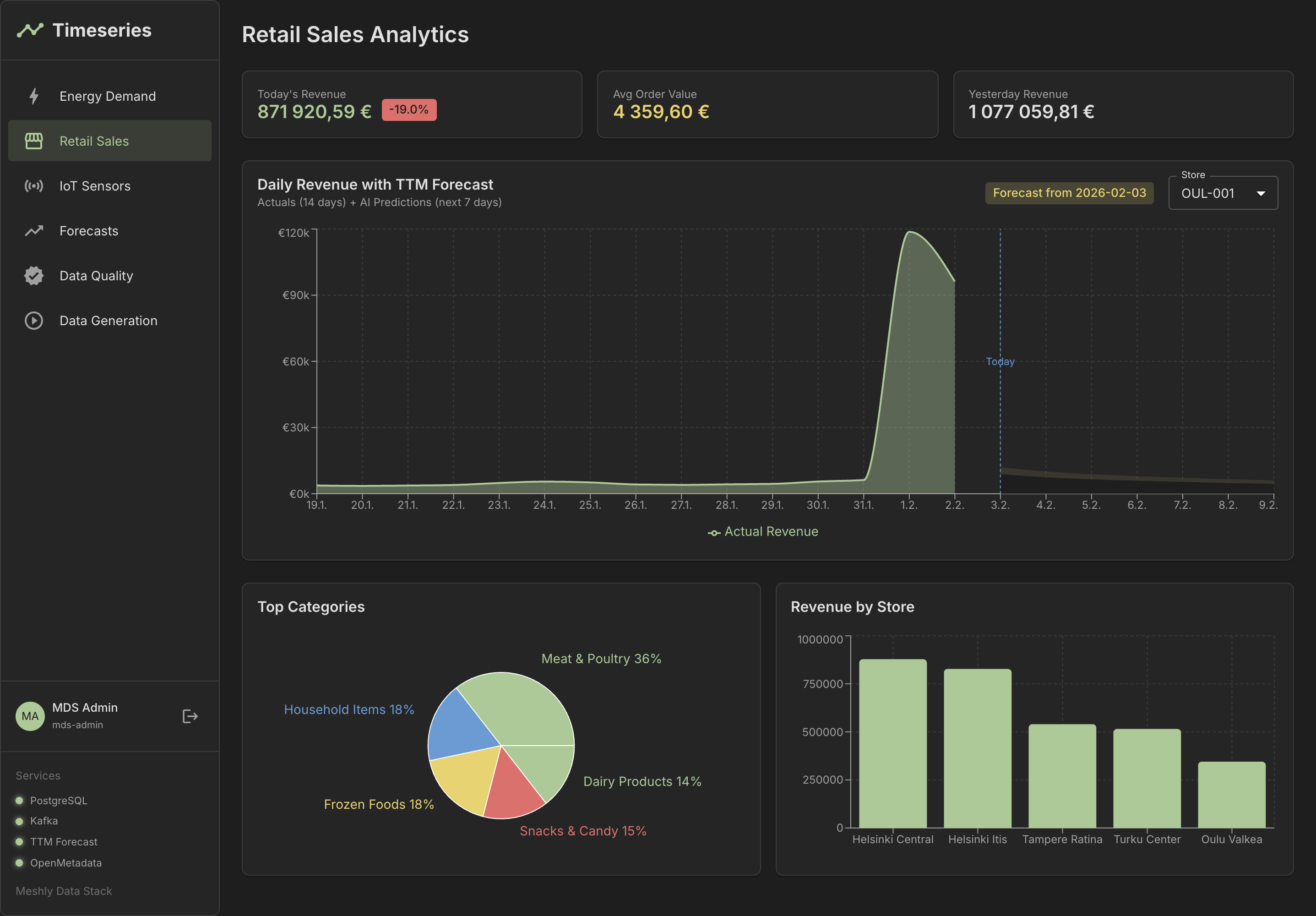
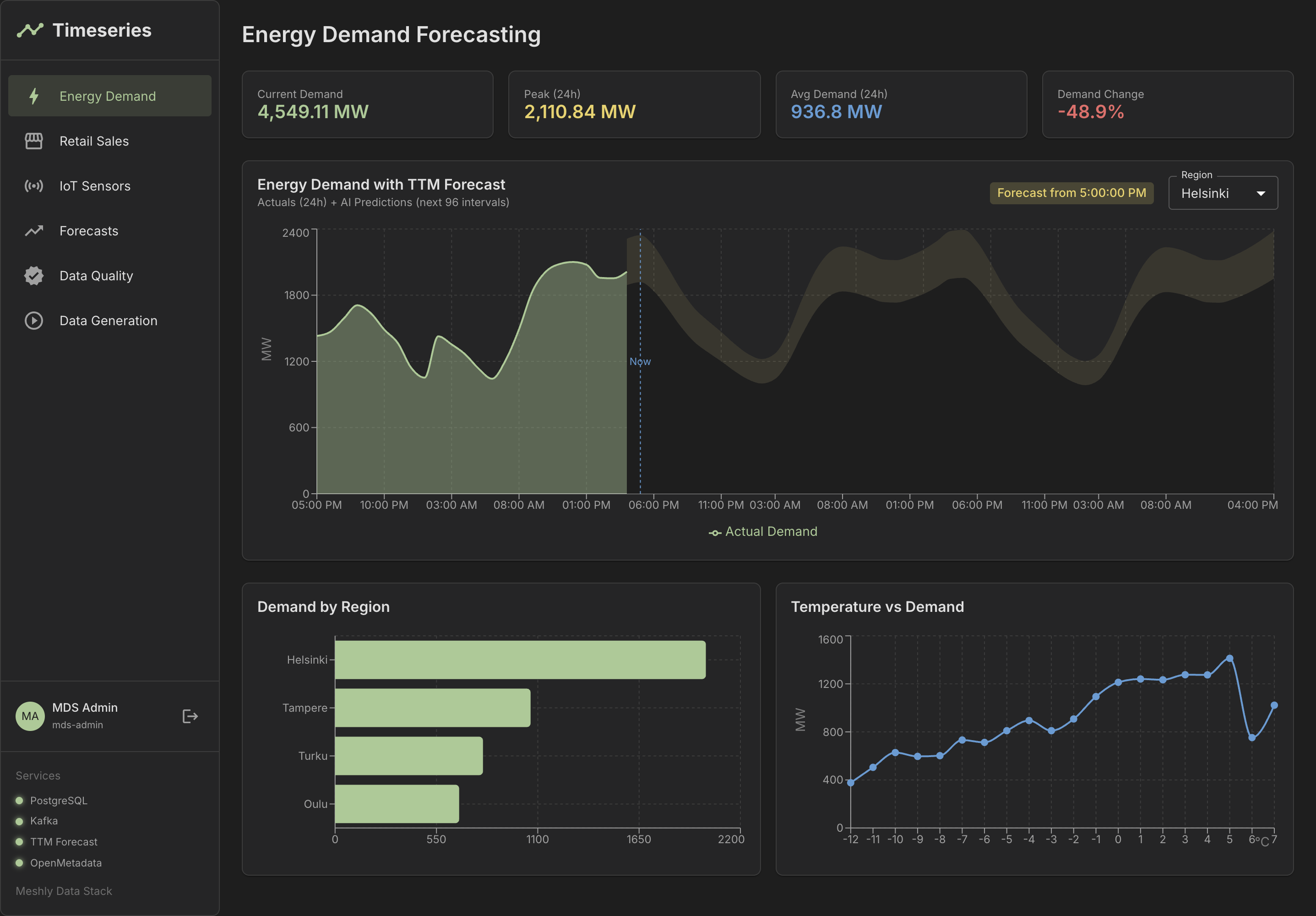
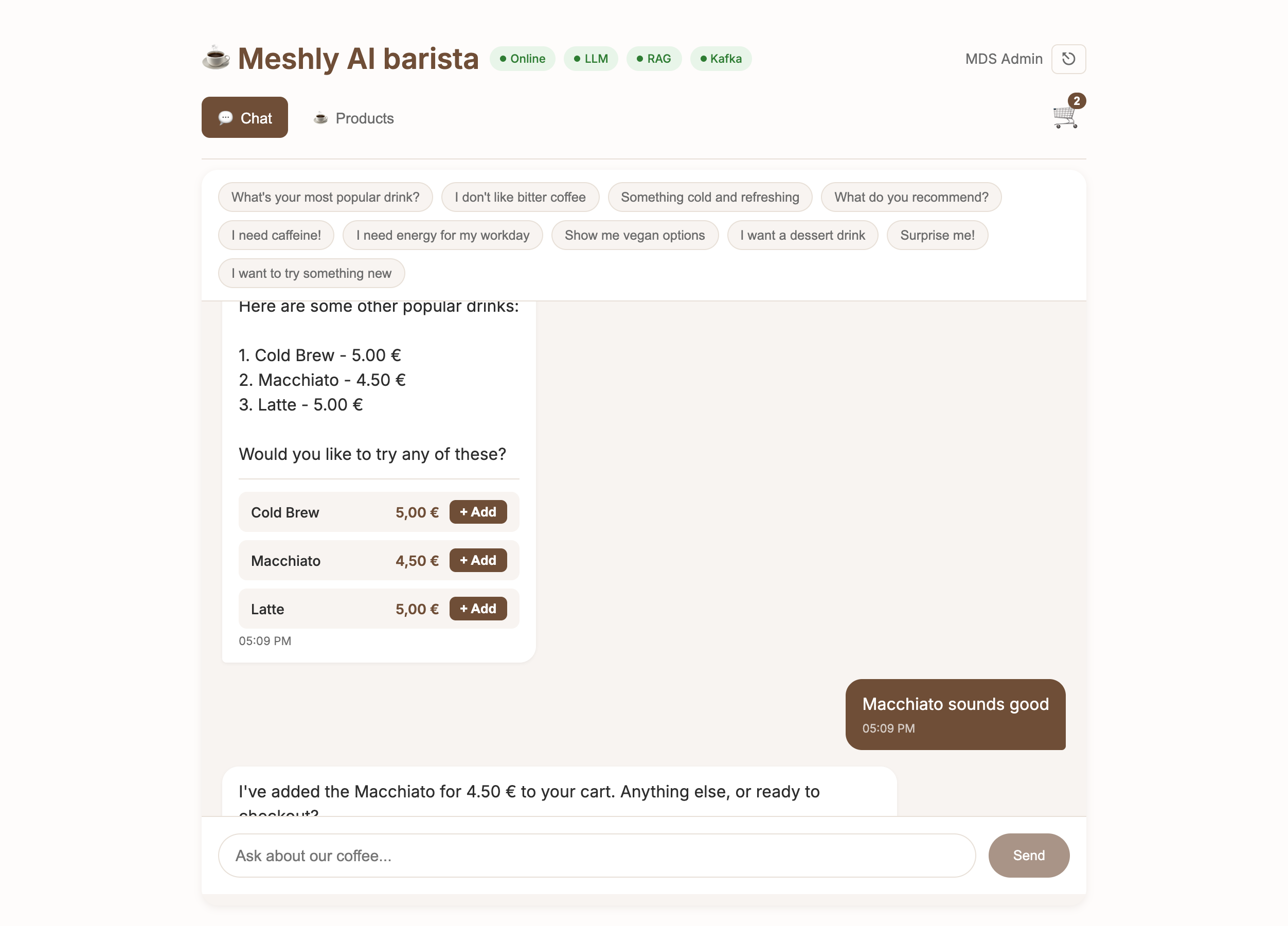
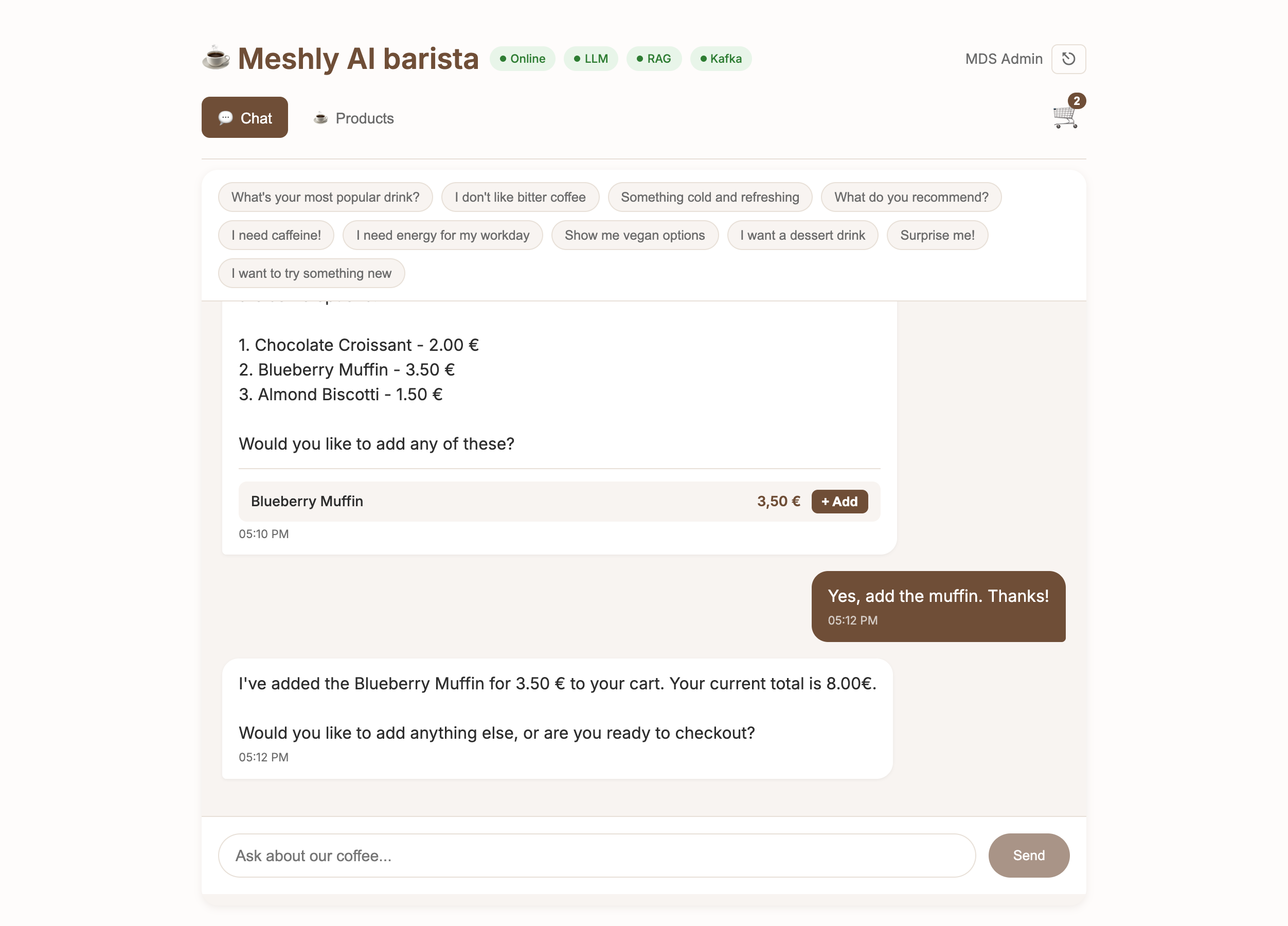
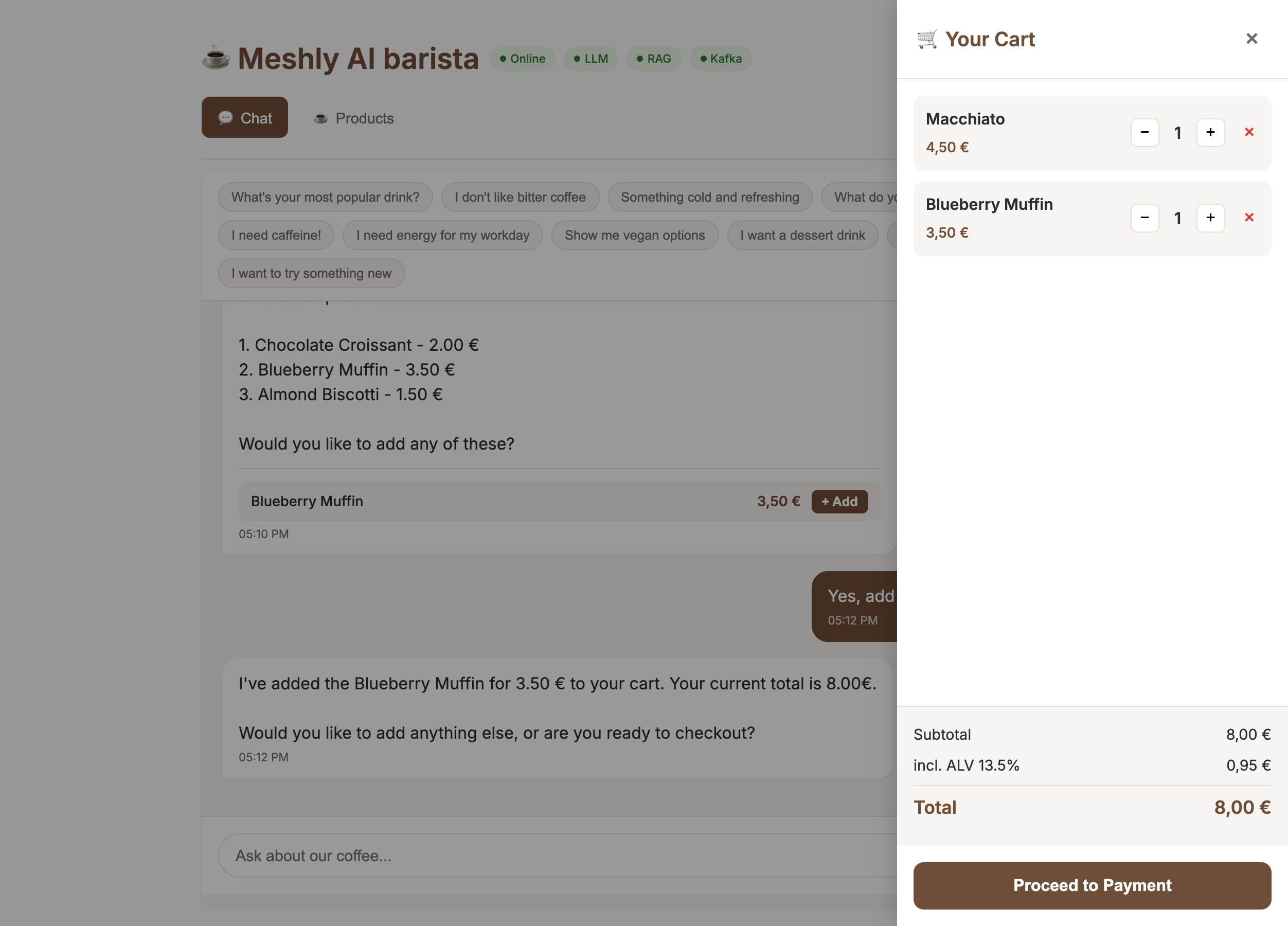
Dashboard Overview
Why Meshly Stack?
Three ways to build a data platform. One takes days.
| Feature | Meshly Data Stack | Build It Yourself | Managed Cloud Platform |
|---|---|---|---|
| Time to Production | Days | Months | Weeks |
| Annual Software Cost | Open source | Variable | €50k–200k |
| Vendor Lock-in | None | None | High |
| Data Ownership | 100% yours | 100% yours | Vendor-accessible |
| Data Residency (GDPR) | Full control | Full control | Vendor-dependent |
| Specialist Roles Needed | Minimal | 2–4 engineers | Managed but locked in |
| AI Data Engineer | |||
| AI-Built Dashboards | |||
| AI-Managed APIs | |||
| Self-Monitoring | Manual | Partial | |
| Self-Documenting | |||
| Deploy Anywhere | |||
| GDPR by Architecture | Depends |
Choose Your Configuration
All tiers include the full AI engineer, self-monitoring, and security stack. No features locked behind higher tiers except processing scale.
Growth
For teams getting started
Starter
or Professional license
Requires: 16GB RAM, 8 CPUs
- Complete data platform (25+ services)
- Streaming, analytics, and dashboards
- Real-time CDC pipeline
- SSO and role-based access control
- Automated secrets management
- AI Data Engineer (8 agents)
- Self-monitoring and auto-recovery
- AI-built dashboards and APIs
- Vector search for AI/ML workloads
Scale
For enterprise data volumes and ML workloads
Professional
or Enterprise license
Requires: 32GB RAM, 12 CPUs
- Everything in Growth
- Visual data flow management (NiFi)
- Enterprise stream processing (Flink)
- Large-scale batch processing and ML (Spark)
- Additional vector database (Milvus)
- Job history server
- Enterprise scale
Enterprise
Your architecture
Contact Us
Requires: Based on your needs
- Integration with existing systems
- Compliance-ready deployment
- On-premises, cloud, or hybrid
- Component substitutions
- Industry-specific configurations
- Dedicated onboarding and support
Not sure which tier fits? Tell us about your data setup and we'll recommend the right configuration.
Ready to Unblock Your AI Work?
Tell us about your current data setup. We'll show you how quickly Meshly Data Stack can get you to AI-ready.
Request a Demo
We'll assess your current setup
Plan Your Configuration
Right-sized for your data and team
Deploy and Connect
First integrations running within days
Ready to get started?
See Meshly Data Stack running with your data, on your infrastructure. We'll walk you through the platform and answer every question.